
Introduction
Every single thread and operation which is performing in computer needs memory. In ideal world we would have unlimited memory with fastest speed possible. However in real world it is not the case. Faster memory elements are more expensive. So during the time the memory architecture has become hierarchical, meaning that fastest elements like Cache are on top with the least amount in size and as going to down of this pyramid, we would have cheaper, bigger and slower elements like DRAM and Disks respectively.
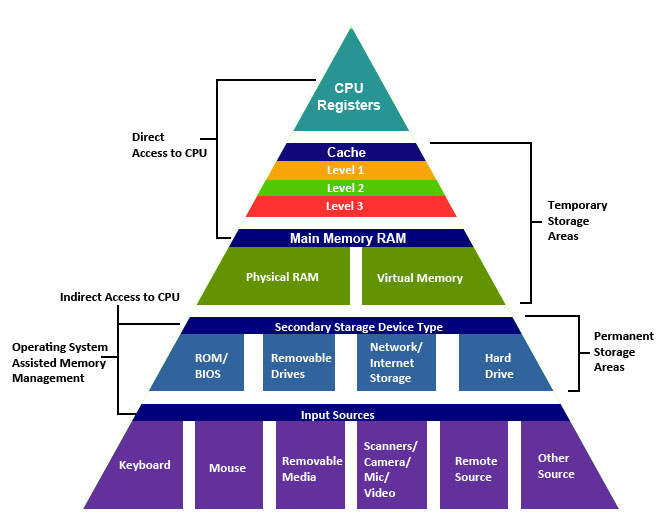 figure 1. Memory Hierarchy [cs.iit.edu].
figure 1. Memory Hierarchy [cs.iit.edu].
Background
Since we cannot have every variables in the cache, this question comes to mind that which memory entities should be in cache and which one should not. There are several different answers to this question which has led to different techniques and algorithms. The most important ones are listed bellow. Two different major category is “Direct Mapped (DM)” and “n-way set associative”. In DM model every memory blocks that have the same ending address will be mapped into same line in cache which as opposed to n-way set associative, there is a choice and we should choose which previously block to replace. For example the LRU (Least Recent Used) is based on the idea that the entity should be replaced that has not been used for longer time and so we have to assign a bit to know which one is used more recently to replace the other(s).

figure 2. Association decreases the miss rate but with some overhead [3].
Most Important Algorithms
- Belady’s Algorithm, refereed to as most efficient one
- LRU, Least Recently Used
- MRU, Most Recently Used
- PLRU, Psudo LRU
- LFU, Least Frequently Used
In addition to famous algorithms and techniques like those mentioned above, there a plenty number of papers that tried to mix these algorithms to get the better performance. For example some works has been done to improve the efficiency through deploying the merits of different algorithms. Such a work is done by Yuval Peress et al. [4]. They tried LRU with some modifications that they call it “protection” of some lines that based on their algorithm they believed that those lines are more important in the sense that they are more likely to be used in short run.
Platform
We used SimpleScalar as our platform to simulate and analyze “SCORE”. Bellow you can see how does this software work. Also there is a great tutorial[2] which is also available at the bottom of the page for downloading.
 figure 3. Architecture of SimpleScalar [2].
figure 3. Architecture of SimpleScalar [2].
Description and Results
In this project we simulated and analyzed the “SCORE” [1] using SimpleScalar. The authors claimed that this approach has a better performance in many different situations. For example the average IPC improvement of SCORE over LRU is 4.9%, and over LIP is 7.4%.
 figure 4. IPC of different replacement policies [1].
figure 4. IPC of different replacement policies [1].
Reference
[2] SimpleScalar Tutorial, by Todd Austin and Doug Burger
[3] Wikipedia, Cache Replacement Policy
[4] Yuval Peress, Ian Finlayson, Gary Tyson, David Whalley. CRC: Protected LRU Algorithm. Joel Emer. JWAC 2010 – 1st JILP Worshop on Computer Architecture Competitions: cache replacement Championship, Jun 2010, Saint Malo, France.
Documents
- SimpleScalar Tutorial, by Todd Austin and Doug Burger
- Paper and Results (in Persian)
- Benchmarks tested
This project was done by me and Mohammad Javad Seyed Talebi. April-July 2014.